벌써 몇년전 일인지요.. 조금 더 있으면 강산이 변하는 시점에 다가오네요...
선배들이 술 사주겠다고 통계 도와달라고 해서 재미 붙이다 보니.. 아 나도 이런쪽에 재능이 있구나 하는생각에 재미를 붙였던 통계.. 기초 통계를 시작으로 해서.. 고등학교때도 관심이 없었던 방정식까지 공부를 하고 보니..
"나도 공부를 못했던 것은 아니었구나 " 하는 생각이 들더랍니다..
그리도 사회생활 언 7년을 넘어선 시점에서 통계는 아직도 저에게 유용한 수단이자 도구입니다..^^
이번에 책을 다 정리하면서.. 문득 메모장에 예전에 AMOS 공부하면서 틈틈이 메모 적어놓은것 있어서 저같이 답답해 하셨던 분들한테 도움이 될까 하고 그래도 옮겨 봅니다...^^
-------------------
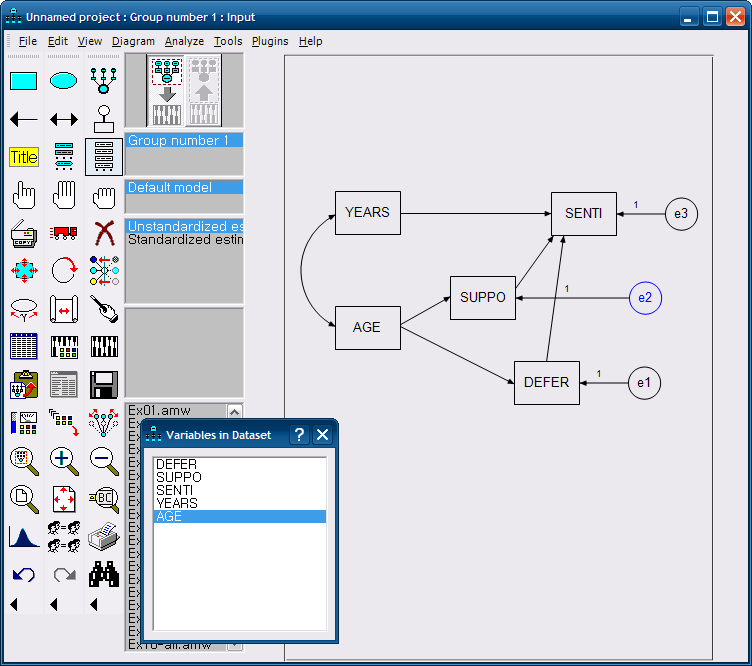
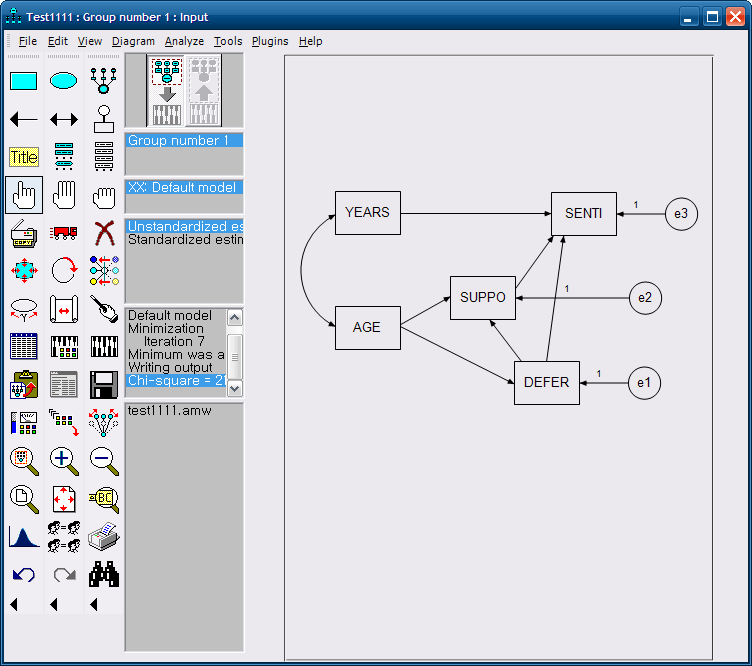
오차항
일상적으로 오차항은 독립변수의 왼쪽
종속변수는 오른쪽에 위치
측정변수 위에 마우스 놓고, 오차하이 자리를 잡을때까지 계속해서 마우스를 누른다. 그럼 왼쪽에 위치하게 된다.
오차항 문구 특별히 신경 쓸필요 없음 (amos)
잠재요인 리그레션 웨이트 = 1
CFA 기본틀 그리고 = 관측변수 3개를 가진 하나의 측정모형을 만듦
좌클릭 상태에서 드래그로 타원 그리기-> 마우스 포인트를 타원에 놓고 마우스 좌클릭 세번
측정오차의 변수명은 plugin기능을 활용하여 자동적을 한꺼번에 입력
(plugins) -> (name unobserved variables) 클릭
손가락 클릭-> 잠재변수 다섯개 좌클릭 -> (plugins-draw covariances) 클릭
EFA를 CFA로 다시 사용한 예 DABHOLKAR AND BAGOZZI (2002) .. 그렇지만 연구자들의 입장에서는 매우 조심스러운 입장이다.
FILE -> DATA FILES -> 해당 파일 클릭
개별로 분석하고 -> 전체로 분석하고...
----------------------------------------
정렬하는 방법은 Ctrl Key 누르고 수직 / 수평으로 갈것
가로 세로 바꾸기 -> Edit -> Space -> Vertically
오차항의 위치변경은 (내생변수)에서 클릭, 클릭 할것
연구모형을 가로 세로 바꾸기는 View -> Interface -> Properties -> page layout -> Orientation -> Landscape
외생변수의 공분산 자동으로 하기는 잠재요인지정 -> menu -> plgins -> draw covariances
경로모형을 시트내에 맞추게 하기 위해서는 네모칸에 화살표 각 방향으로 간것..
-------------------------------
5개의 잠재변수를 가지고 확인요인분석 실시 후 마지막 두개의 판별타당성에 문제가 있을경우
둘 중 하나 혹은 둘다를 제거하는 방법을 선택.
적합도 지수를 고려하여 더 좋은것을 선택할것
선행연구 대부분이 3-4개의 관측변수 설정
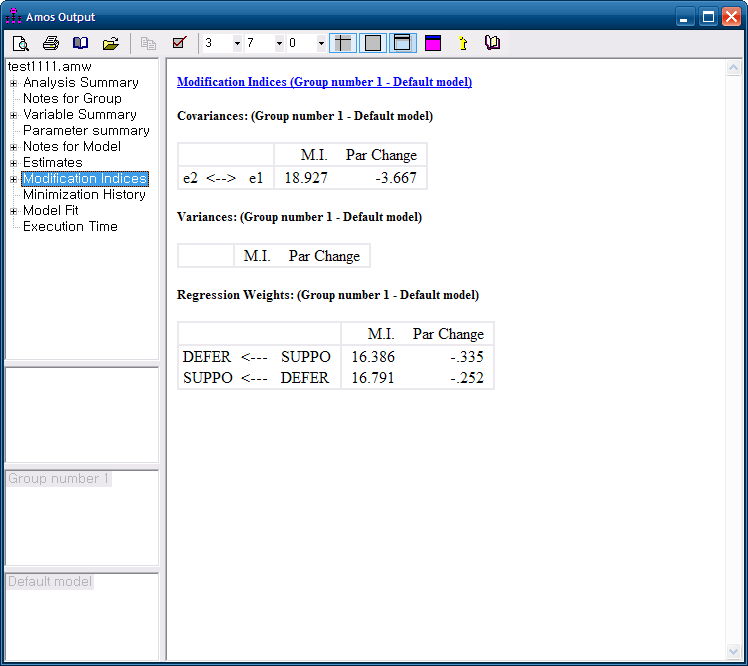
수정지수는 카이제곱값이 얼마나 작아지는가에 대한 값이다.
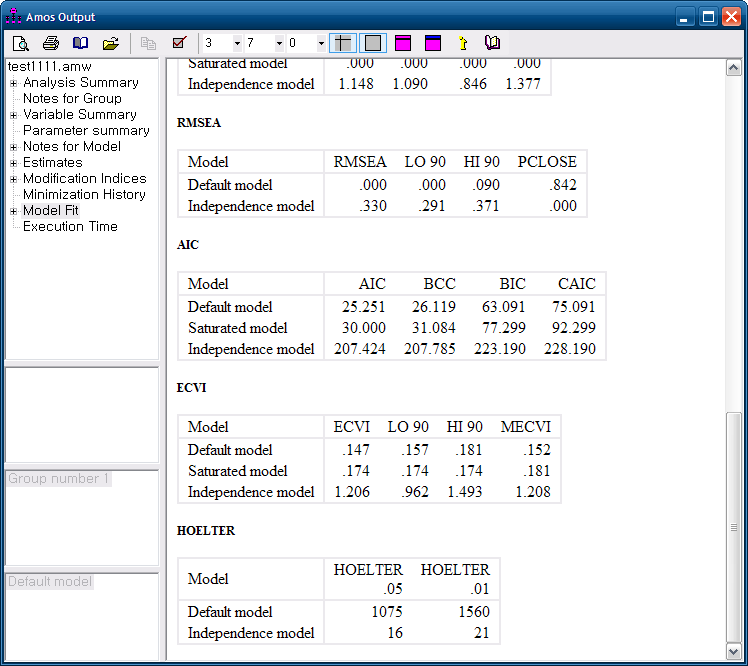
RMR < 0.05 GFI > 0.90
AGFI >0.90 & GFI > AGFI 가 되어야 함
RMSEA <0.05 / TLI, NFI, CFI >0.09
NOTE FOR MODEL에 오류가 생길경우 분석결과 신뢰가 어려우므로 오류를 수정해야 한다. 가장 많은 오류는 음오차분산이다
분산은 제곱의 개념이기 때문에 음수가 나올수 없다. 만약 X가 음오차 분산이라면 다음과 같은 메시지가 뜬다.
해결방법은 해당 변수에 마우스 우클릭 -> OBJECT properties-> parameter탭의 variances에 0.0005를 입력해주면 된다.
그러나 음오차 수정을 하기에 앞서 모형을 수정해봐라..
6
그 다음 model fit을 확인 카이제곱 RMSEA GFI AGFI NFI RFI IFI TLI CFI 를 본다
지수 체크 후 잠재변수와 관측변수간의 상관관계인 윕실런 유의성을 체크 /비표준 웹실런과 C.R은 양수가 되어야 한다 (유의해야 함)
준거변수 맞추기..
수정
-----------
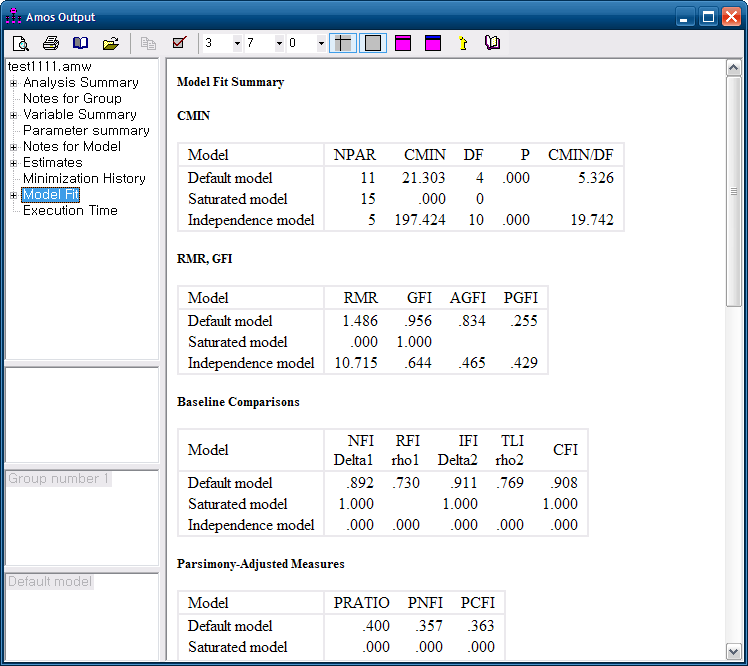
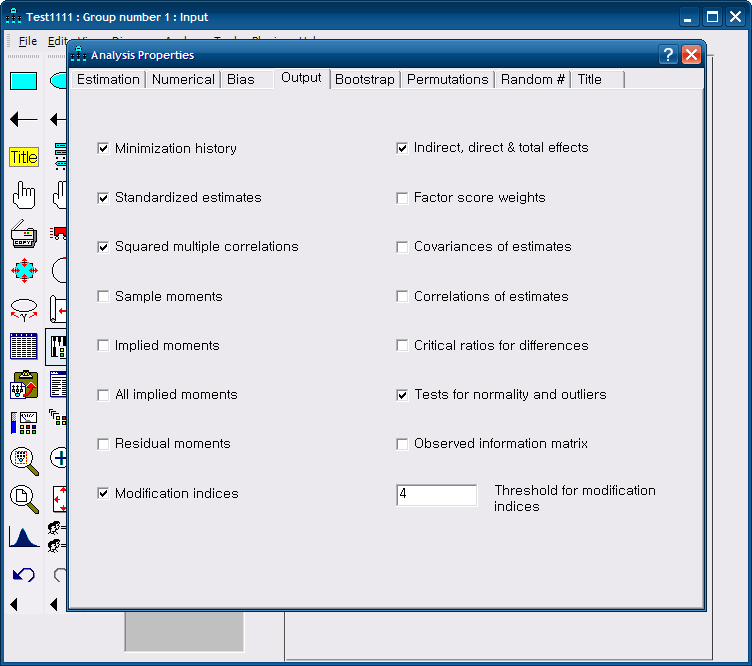
amos 아웃풋 창에서 여러가지 지수가 제시된다,
적합도 지수 중 카이제곱 값을 보면 카이제곱=19.576 d.f=2 p=0.000 으로 나타났다. 이는 카이제곱의 p값이 0.05보다 커야 바람직하다는 기준치를
충족시키지 못하고 있다. 그러나 적합도 지수 중 카이제곱은 표본의 크기가 클 경우 기준치를 충족시키기는 어렵다는 점을 고려할때 큰 문제가 되지 않는다
다른 적합도 지수인 RMR은 0.038로 나타나 기준치를 충족시켰으며 GFI도 .960으로 나타나 기준치를 충족시켰다. 이러한 내용을 고려할때 본
잠재요인의 측정 적합도 지수는 수용할만하다고 볼수 있겠다.
적합도 지수가 수용 가능하며 요인부하량을 점검해야 한다. 이는 통계적으로 유의해야 하는데 만약 유의적이지 못하면 그 항목은 제거해야 한다.
REGRESSION WEIGHTS가 요인부하량이다. .
--------------------------------
regression weights (인과계수)에서 c.r값은 spss 에서 언급하는 t값과 동일한 의미이다. 그러므로 +- 1.96보다 클때는 그 의미가 있는것이다
C.R값은 인과계수를 표준오차로 나눈 값이다
표준화된 인과계수는 절대치의 대소나 부호를 보면서 인과관계를 파악한다.
VARIANCES 에서는 각 잠재요인과 측정변수의 분산 값을 보여준다 ESTIMATES 값이 마이너스로 나오면 안된다. 이럴경우 HEYWOOD CASE라 한다.
이 케이스가 발생하였다면, SMC 값과 적합도 검정결과를 파악하는 것은 무의미 하다. 제일먼저 처리를 해야 한다.
1) 헤이우드 케이스를 제거하던지 2) 아니면 변수를 그대로 사용하기 위해서는 일반적으로 오차항을 0.005와 같이 아주 작은 값으로 고정시켜야 한다. 오차분석을 0.005로
제한하면 오차분산이 마이너스로 나타나지 않는다. 오차분산을 0.005로 고정시키는 이유는 적재치를1보다 작은 값으로 하기 위해서이다.
--------------------
CMIN/DF -> 일반적으로 2이하이면 모델이 적합하다고 한다.